
译自Chem-Station网站日本版 原文链接:機械学習は、論文の流行をとらえているだけかもしれない:鈴木ー宮浦カップリングでのケーススタディ
翻译:炸鸡
虽然大多数有关机器学习的论文会报道:“建立的模型成功预测了反应产物和产率,但是近期JACS上有一篇论文报告了经过机器学习建立的模型并不能很好地预测最佳反应条件。下面是关于这篇论文的详情介绍。
背景
机器学习已经在各个领域得到了应用并取得显著的成效,如果想要提高计算机的预测的准确度就需要在机器学习过程中制定明确的学习规则和高质量的数据集,否则计算机做出的预测结果没有使用价值。举个用于化学研究的机器学习的简单例子,如果在机器学习中给计算机提供的数据集是大量清楚的格式化的化合物反应案例,那么计算机经过机器学习后就能很准确地预测物质的反应活性了,即使对未出现在数据集中的化合物同样能做出反应活性的预测。然而,涉及到选择特殊的数据集或存在难以控制的变数,机器学习的优势就不是很明显了,例如指令计算机制定出一条合成路线,计算机制定出的合成路线很有可能会是条实际不可行的路线,合成的收率很大一部分取决于人和环境,通过机器学习做出的预测不是很准确。
在反应条件优化中,底物和溶剂的选择也是重要的问题,经过机器学习的计算机所能提出的最佳反应条件只不过是机器学习中使用的数据集中的所有论文里最常使用的反应的条件,计算机自己没有提出原创性的主张。为了解决这个问题,论文作者以杂芳基–异芳基或芳基–异芳基Suzuki-Miyaura偶联反应作为机器学习的主题,尝试用机器学习探索基Suzuki-Miyaura偶联反应的最佳反应条件。然而,机器学习的成效并不显著,计算机给出的最佳条件只是给出了最常见的条件(论文原文的Introduction部分也提到了这一点。)。
结果与讨论
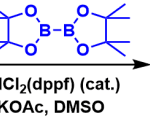
从背景我们已经知道了该论文的结论了,接下来我们来看看详情。测试反应是如下图所示的反应,我们从Reaxys(Reaxys是2009年1月由Elseiver公司推出的化学数值与事实网络数据库。它将著名的拜耳斯坦数据库、盖墨林数据库和专利化学数据库(Patent Chemistry)的内容整合在一个平台下,包含超过2800多万反应、1800多万物质、400多万文献,每年都在不断增加)摘取数据构建了数据集。数据集中收录有16748个反应的催化剂,碱和溶剂数据,以及13337个反应的催化剂,碱和溶剂,以及温度数据。未列出产率的反应,未列出钯化合物的反应和专利的反应没有被收录。
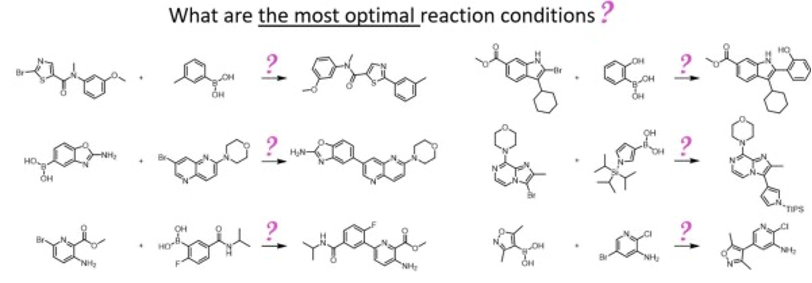
用于实际检验经过机器学习后计算机建立的模型能否选出最佳的反应条件的测试反应(来自:论文)
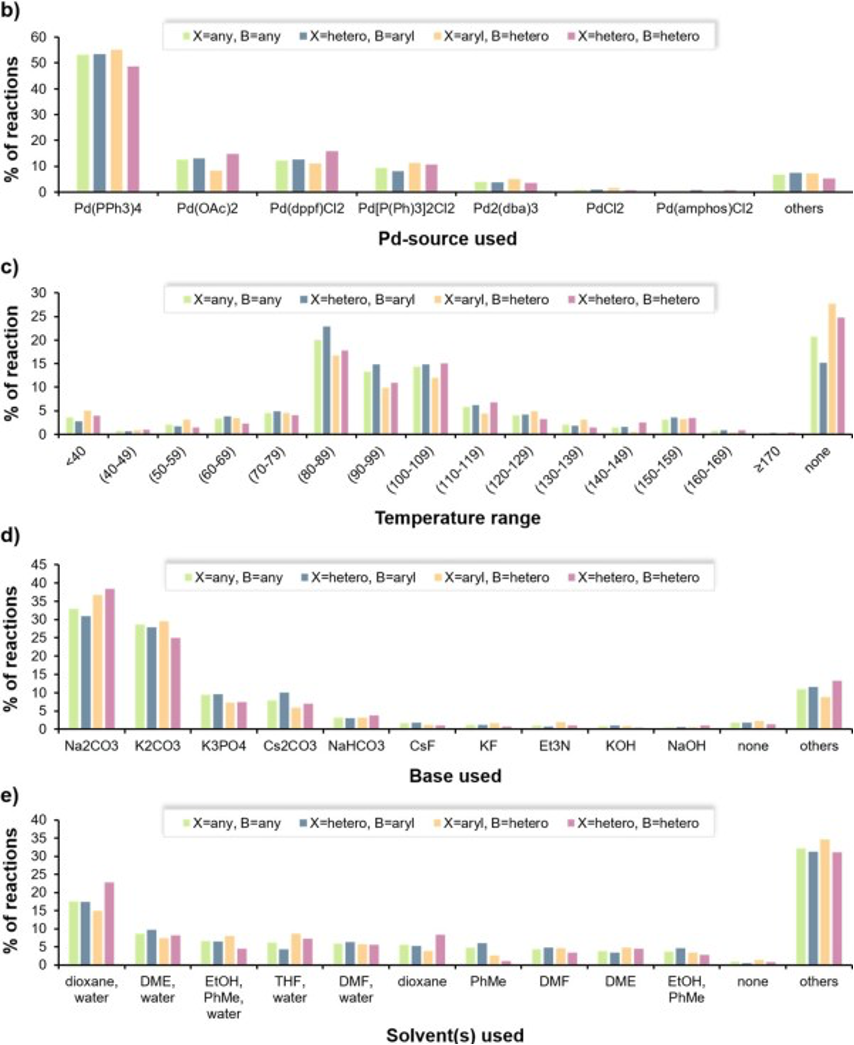
首先,我们将数据集收录的的反应条件总结为直方图。催化剂多是Pd(Pph3)4,反应温度多在80°C到109°C之间,大多数反应的碱是碳酸盐。至于反应溶剂的选择没有出现特别偏向选择某一溶剂的倾向。基于这样的结果,本研究的重点决定放在预测溶剂和碱上。具体研究方法为:令计算机从数据集中学习最佳反应条件的溶剂和碱的组合,之后通过测试反应的实际产率来评估模型能不能准确选择出最佳反应条件。
首先,在具有两个隐层和两个输出层(碱和溶剂)的前馈神经网络(前馈神经网络,为人工智能领域中,最早发明的简单人工神经网络类型。在它内部,参数从输入层向输出层单向传播。有异于循环神经网络,它的内部不会构成有向环。)中进行了预测。关于输入层(描述分子结构的方法),我们尝试了以下四种方法。
- Morgan fingerprints
- RDKit library
- 1和2的组合
- 1的Autoencoder
结果是:模型预测的最佳反应碱和溶剂的组合几乎就是数据库里所有论文的碱和溶剂的组合中人气最高的组合。所以可以说神经网络模型只能选出论文里最被频繁使用的组合,无法做到进一步提出新的﹑潜在的最佳的组合。
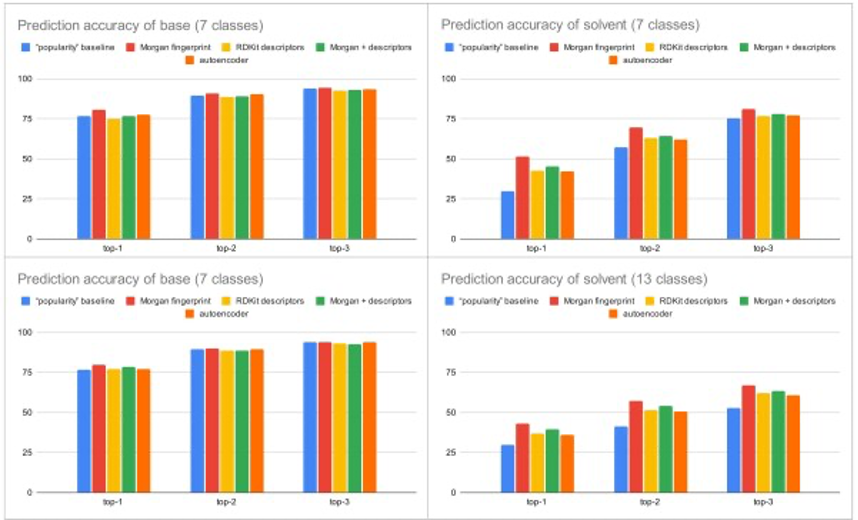
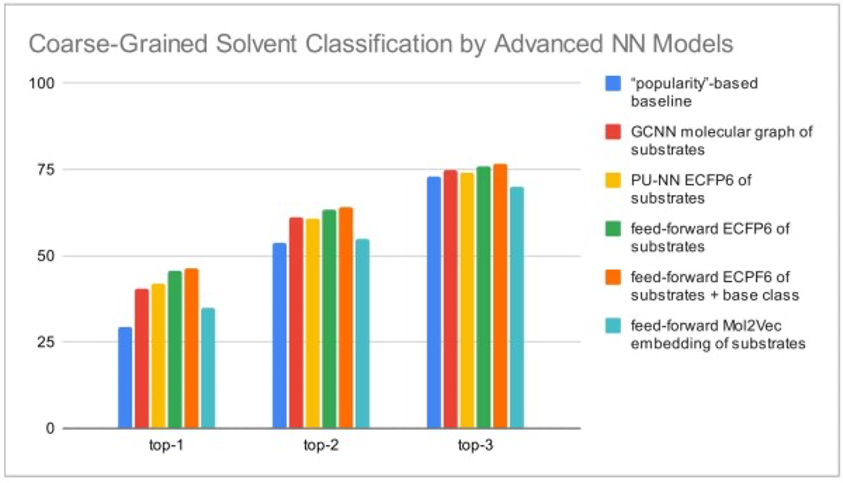
碱基/溶剂=7/7和7/13分类下的准确性(top-1显示的是每个模型在6个测试反应中第一个给出的答案即为正确的概率,top-2和top-3分别显示的是第一到第二回答和第一到第三个回答里有正确答案的概率)(来自:论文)
上层的7种溶剂选项: {alcohols, water/polar solvents, water/alcohols, water/amides, water, amides}, {water/aromatics, alcohols/aromatics, water/alcohols/aromatics}, {aromatics}, {ethers}, {water/ethers}, {other}
下层的13种溶剂选项: {water/ethers}, {ethers}, {water/alcohols/aromatics}, {water/amides}, {alcohols/aromatics}, {aromatics}, {amides}, {water/aromatics}, {low boiling polar aprotic solvents/water}, {water/alcohols}, {water}, {alcohols}, {other}
碱的选项:{carbonates}, {phosphates}, {fluorides}, {hydroxides}, {amines}, {acetates}, and {other/miscellaneous}
接着论文尝试通过Graph Convolutional Network和统计校正(PU-NN模型)的辅助来提高模型预测的精度。Graph Convolutional Network是一种将深度学习应用于图表数据的方法,在化学领域的机器学习中可以直接处理分子图(结构式)。PU-NN模型能够将未经报导的碱基和溶剂的组合也纳入了考虑范畴。
碱基/溶剂=7/7类别下的正确性(来自:论文)
结果显示:第一个回答是正确的概率低于50%,第二个,第三个回答依次也是按照论文里最频繁使用的组合的顺序。论文还使用Extended Connectivity Circular Fingerprints和Mol2Vec构建了前馈模型,但结果没有太大变化。
此外,为了提高模型预测的准确性,研究人员决定补充关于反应产率的信息。在本研究中,先令计算机预测了所有碱基和溶剂组合的各自的产率,并计算了在这些预测的产率数据中,第一高到第三高的产率数据中能找到实际反应的产率的概率。虽然用不同的输入方法构建了模型,但在所有模型中都没有太大的差异。另一方面,预测的最佳和最劣条件下的收率差为5-10%,低于实测值20-30%。这是因为解释变量对产率的反应不敏感,这也导致了从第一高到第三高找到实际反应的产率的概率较低。模型所预测的组合都是低于人气组合基线的组合。
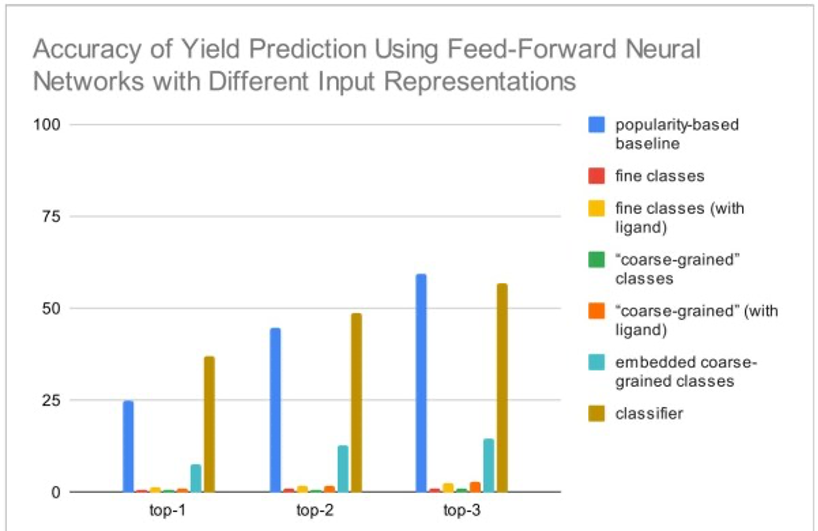
预测收率的正确性(来自:论文)
最后,用三项先前的研究中开发的模型进行了类似的试验。从美国专利和Reaxys数据库里提摘取的反应数据一起组成了数据集。结果显示,只有Rel-GAT模型的预测出的组合是高于人气基线的。
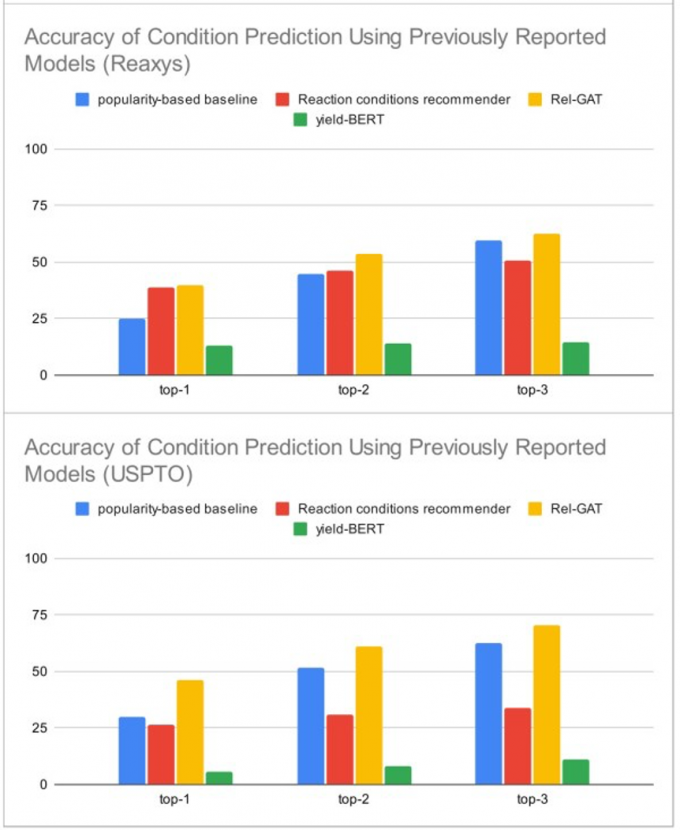
使用先前研究中开发的模型来预测反应产率的准确性(来自:论文)
总结
结论是经过机器学习的模型能做到的仅仅是追随数据集的热门组合,并不能超越它做出更准确的预测。论文作者们推测,这是因为选择的是相关研究领域中最常报道的反应条件或者实验室中传统的最偏好的底物和溶剂,所以论文中的反应对于机器学习的实施来说是不公平的。如果要更好地让计算机预测,需要系统地,标准化的且多次实验的结果,在全自动合成实验等方面认为是必须的。当然,在实现这样高要求的数据普遍化之前,机器学习的模型需要参照论文里的频出条件考虑反应的趋势。
个人想法
我这次介绍的内容比较浅层,但是机器学习的各种方法都出现了,我个人觉得本篇内容值得一看。一般论文的内容都是用AI成功进行高精度预测的案例,但在本论文中提出了不顺利的例子,并考察了其中的原因,这一点是非常独特的。在合成研究中,每个实验室都在各自的设备和环境中进行实验,并在论文结果和考察部分自由选取和报告想要公布的数据。因此,即使在论文中可以比较结果,从各种论文中提取数据,误差也很大,因为并不是均一地重复调查底物和溶剂,所以作为模型的数据集是不合适的,这是一个很好的例子。在所有的反应研究中,很难对条件和论文的形式进行标准化,所以笔者认为有刊登讨论专门针对在标准化的条件下得到的数据的论文杂志是很好的。
本文版权属于 Chem-Station化学空间, 欢迎点击按钮分享,未经许可,谢绝转载









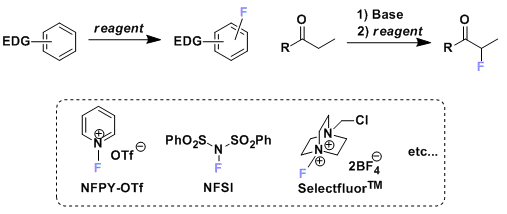











No comments yet.