

译自Chem-Station网站日本版 原文链接:ゼロから学ぶ機械学習【化学徒の機械学習】
翻译:炸鸡
什么是机器学习
机器学习,顾名思义,就是“让机器自己自动学习”。提到机器学习,有一个概念不得不提——人工智能。这个名词相信很多人都不陌生。“人工智能”这一概念最早兴起于上世纪50年代。人工智能是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及系统应用的一门技术科学,即人们想办法让机器模仿、延伸和开拓人的智能,比如说“人像识别”“机器翻译”,都是人们利用计算机技术赋予机器以“人”才有的能力(分辨人脸,翻译语言)。
机器学习属于人工智能的一种手段。人工智能的目的是想让机器拥有人一样的智能甚至拥有超越人的智能,要想实现这一目标,其手段之一就是让机器自己学习,让机器自己变得“聪明”起来。通过对计算机大量输入数据,让计算机自己习得大量数据背后的规律,那么计算机面对陌生的数据集时就能预测结果了。
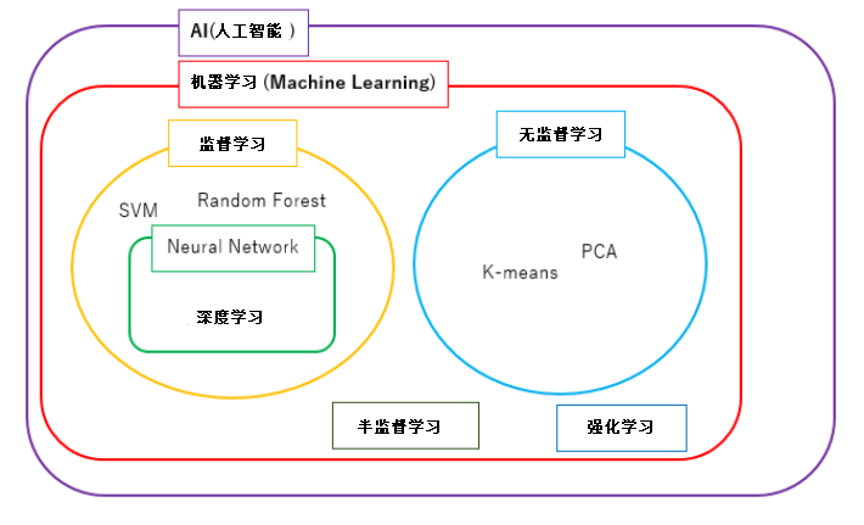
图1 机器学习相关术语的分类(虽然强化学习有时被归类为无导师监督学习,但这次我们不按有/无导师学习对它进行分类。另外,本期科普将人工智能简写为AI(Artificial Intelligence),机器学习简写为ML(Machine Learning)。
有无标签
在机器学习中,为收集数据并预测相关的结果,常采用两种类型的数据处理方法。
•监督学习(Supervised learning)
•无监督学习(Unsupervised learning)
有监督学习和无监督学习又分别有很多小类。监督学习的目标是用标签为基础建立模型,以获得对于未知数据做出正确预测的泛化能力1。这里所说的标签,可以理解为机器的输出(通俗点来说,把机器拟人化,在它参加考试(面对未知数据时)前对它进行做题训练(机器学习),一边做题,一边告诉他题目的答案(标签))。而无监督学习的目的是分析数据本身的结构和特征2。只经过监督学习,计算机可以自己建立模式也可以预测未知的数据。在监督学习之前先进行无监督学习有助于人们理解计算机做出的预测结果,无监督学习有时会提高监督学习的准确性。除了监督学习和无监督学习外,机器学习还有强化学习(Reinforcement learning)和半监督学习。
监督学习的种类
监督学习又分为“分类(Classification)”和“回归分析(Regression)”两大类。分类即计算机对输入的数据的反应是预测一个分类标签比如0和1),如果计算机通过对连续的值(并根据线性或非线性关系)进行预测,则是回归分析。
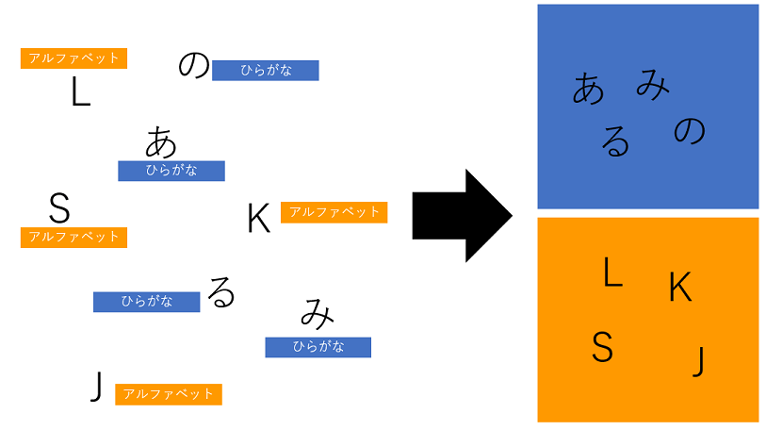
图2 分类
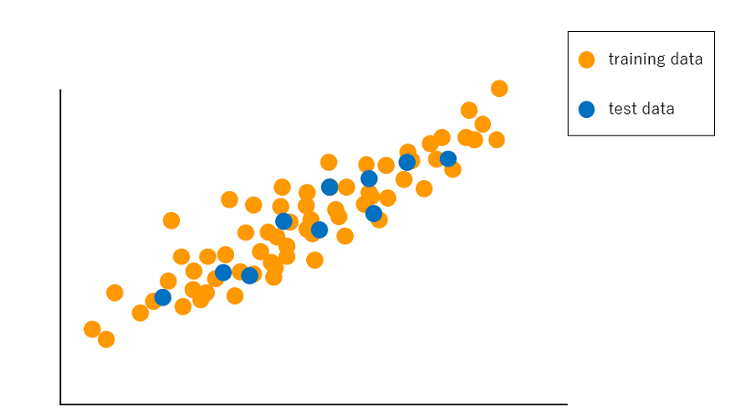
图3 回归分析
监督学习的算法有如下几种,有只能用于分类的算法,也有能用于分类和回归的算法的。此外,这些算法各有各的特征
・Random Forest
・AdaBoost
・Support Vector Machine (SVM)
・kNN(K-近邻算法)
・Neural Network
・Logistic Regression
・Liner Regression
无监督学习的种类
无监督学习包括聚类(Clustering)和维度缩减(Dimensionality reduction)等。常见算法如下:
・PCA
・k-means
・t-SNE
机器学习使用的编程语言
现在使用的编程语言除C/C++,Java、JavaScript、Swift之外还有很多门语言。对机器学习而言经常用到以下2种编程语言。
・Python
・R
Python这门编程语言的逻辑不是很抽象,可以说是一门初学者能很好地适应的通用型编程语言。因为Python的通用性、并拥有丰富的机器学习库,Python经常被用作机器学习的算法。R语言更有利于数据分析。顺便说一下,笔者在撰写本篇文章时只学了Python编程语言。因为笔者用的是Python,所以笔者想从这里开始就只聊Python了,请见谅。
化学中特别使用的工具
以上就是关于机器学习的大体介绍,并没有涉及到化学知识。
但从现在开始进入到专门服务于化学的机器学习介绍。在化学领域,结构式为人们提供了丰富的信息,但构造式对机器来说根本读取不到什么信息。这就需要出台一部能将只有人能看懂的构造式转变为机器能够理解的形式的转化规范了(好比人和机器是两个物种,文字不通,需要通过一个“语言转换器”将人类文字转变为机器文字)。SMILES就是这样的一个工具。SMILES是Simplified Molecular Input Line Entry System<简化分子线性输入规范>的缩写。SMILES能将构造式转变为一串的文字和符号的形式方便机器读取。通过编程、软件等方式,SMILES又可以将一串文字和符号转变为结构式。SMILES有几种,这里我想给大家介绍其中一个canonical SMILES4。
例如,fingerprints(意为指纹)是一种构造式表达方法,它使结构式能被SMILES读取,然后用于计算和机器学习。fingerprints也有几种类型。ECFP算法是将结构表达式转换为fingerprints表达方法的算法5,6,7之一,其大致算法流程如下所示:
- 对于氢原子以外的原子,以原子序数等特征为基础,分配整数标识符。
- 令各个原子的标识符反映出相邻原子的标识符,如此反复更新标识符。由此,可以得到含有部分结构信息的原子识别符。
- 删除重复的标识符。
ECFPs(扩展连通性指纹)是Extended-connectivity fingerprints的缩写,ECFP fingerprints最后的“成品”是经过上述算法之后得到的最终标识符。
图4展示了我使用过的fingerprints之一的Morgan fingerprints的例子Morgan fingerprints的结构信息由大量排列0和1的位串表示(根据fingerprints的类型,描述符的数量、位串或整数列的数量会有所不同8)。复杂的化学结构式竟能用简单的数字排列来表达,真是令人惊讶。
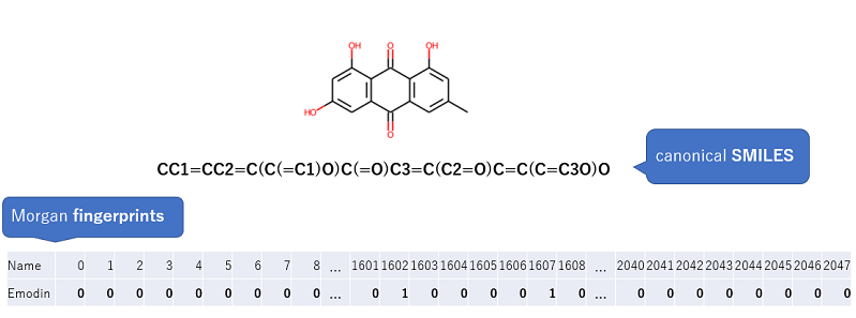
图4 SMILES和fingerprints的样例(Emodin的canonical SMILES来自参考文献4)
总结
本篇文章我列举了关于机器学习我能想到的所有基础术语。以列表方式介绍的监督学习、无监督学习的种类还有很多,每一种也各有特点。信息还不是很充分,这次就讲到这里。
参考文献
[1] 杉山将 著, イラストで学ぶ 機械学習―最小二乗法による識別モデル学習を中心に, 2頁, 講談社, 2013
[2] 大曽根, 関, 米田 著, 現場で使える!Python機械学習入門, 136頁, 翔泳社, 2019
[3] 金子弘昌 著, 化学のためのPythonによるデータ解析・機械学習入門, 129頁, 134頁,オーム社, 2019
[4] Toluene (Compound), PubChem,
https://pubchem.ncbi.nlm.nih.gov/compound/Toluene#section=InChI-Key (最終閲覧日:2021年3月20日)
[5] Kensert, A.; Alvarsson, J.; Norinder, U.; Spjuth, O. Evaluating Parameters for Ligand-Based Modeling with Random Forest on Sparse Data Sets. J. Cheminform. 2018, 10 , 1–10. DOI: 10.1186/s13321-018-0304-9.
[6] Rogers, D.; Hahn, M. Extended-Connectivity Fingerprints. J. Chem. Inf. Model. 2010, 50, 742–754. DOI: 10.1021/ci100050t.
[7] A Practical Introduction to the Use of Molecular Fingerprints in Drug Discovery, https://towardsdatascience.com/a-practical-introduction-to-the-use-of-molecular-fingerprints-in-drug-discovery-7f15021be2b1 (最終閲覧日:2021年4月8日)
[8] Elton, D. C.; Boukouvalas, Z.; Butrico, M. S.; Fuge, M. D.; Chung, P. W. Applying Machine Learning Techniques to Predict the Properties of Energetic Materials. Sci. Rep. 2018, 8, 1–12. DOI: 10.1038/s41598-018-27344-x.
記事全体の参考
[9] 神崎洋治 著, 図解入門 最新人工知能がよ~くわかる本, 秀和システム, 2016
[10] 下田倫大 監訳, scikit-learnとTensorFlowによる実践機械学習, オライリー・ジャパン, 2018
[11] 中田秀基 訳, Pythonではじめる機械学習, オライリー・ジャパン, 2017
[12] Kebin P. Murphy, Machin Learning A Probabilistic Perspective, 2頁, 12頁, The MIT Press, 2012
封面图片来自这里
本文版权属于 Chem-Station化学空间, 欢迎点击按钮分享,未经许可,谢绝转载



















No comments yet.